Atomic Memory Access
Introduction
This document explores the concept of atomic memory access in computing systems.
Atomic access to memory, while conceptually simple, is dependent upon many
system factors that are not always obvious to software practioners.
Many software engineers become accustomed to working with a single hardware
platform, and in this mode it is easy to lose sight of the more general
issues.
For example, many software engineers have only worked on systems that have
a single CPU, where atomicity is only an issue between interrupt service
routines and threads. Thus, if a single instruction is not interruptible,
and a single instruction performs many memory operations, then atomicity
is guaranteed by the use of a single instruction. Consider the
read-modify-write instructions of a CISC CPU such as increment and decrement
instructions. If the software engineer subsequently proceeds to a RISC
architecture machine, where no such instructions exist (loads,stores, and
arithmetic operations are all separate instructions), then the old assumptions
no longer apply.
In spite of the preceeding, the remainder of this document will narrow its
focus and examine atomicity as it pertains to memory access only, and
leave interrupt synchronization for another document.
Worst Case Scenario
To expose the micro details of atomicity, we will fabricate a worst case
scenario. Consider a system with the following properties:
- A 32-bit RISC CPU with no read-modify-write instructions.
- An 8-bit RISC CPU with no read-modify-write instructions.
- An unarbitrated-asynchronous dual port memory.
A key feature of this system is the unarbitrated asynchronous dual port
memory that is shared betwen the two CPUs. The 8-bit CPU is connected
to one port of the memory, and the 32-bit CPU is connected to the other
port of the memory.
The unarbitrated-asynchronous nature of the memory is such that either
CPU may read or write a location (octet) at any time. The memory makes
no attempt to serialize access to individual memory locations. Thus
one CPU may be in the middle of writing a location while the other
CPU reads the same location.
Under these conditions, the CPU performing the read operation is not
even ensured that it will read the previous value of the location
or the new value (as being written by the other CPU.) Some of the
bits may have changed and others may be in transition when the reading
CPU read-cycle completes.
If the memory technology is such that the outputs of the registers
for each bit may become indeterminate whether or not the new value
being written is the same as the old value, then we cannot reliably
use a single octet memory location as a flag with which to synchronize
access by the two CPUs.
Factors
- Single CPU System
- Single instruction atomicity
- Not read-modify-write instruction
- Not divisible by a CPU interrupt.
- Multi-Master Shared Memory
- Symetric CPUs
- Asymetric CPUs
- CPU / DMA
- Endianess
- Maximum Access Size -
- Shared Memory Type
- Single Port
- Bus Arbitration for memory
- Bus width limits atomic data size
- Individual master atomic data size may be smaller than bus width.
- Multi Port
- Serialized Access
- CPU's synchronized to memory
- Wait state / cycle acknowledge.
- Arbitration overhead
- Throughput Performance Loss on collision
- CPU and Memory clocks synchronized.
- Collision not possible
- No Throughput Performance Loss
- System hardware design constrained by need to share clocks
- Asyncronous Access
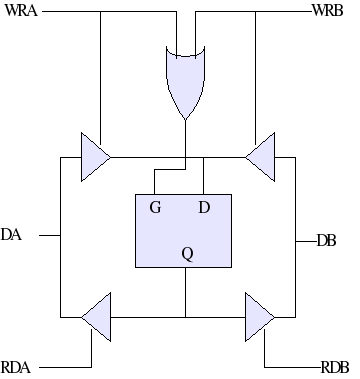
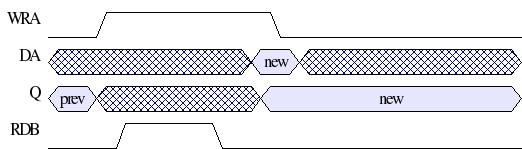
- Cache Coherency
- Cache Line Size
- Hardware Enforced Snooping
- Software Enforced
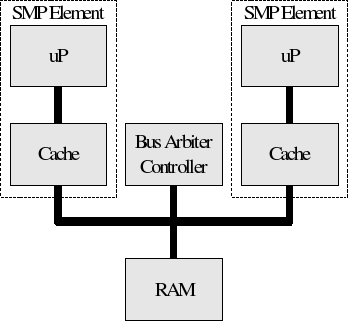
Symetric Multi Processing is an architecture where two or more
processors of the same type share a single memory space. To relieve bus
contention, each processor typically has its own cache.
In SMP systems, the bus protocol is managed by a
bus controller that controls access to the bus.
The bus protocol generally includes mechanisms for enforcing
coherencey between the caches and RAM. This hardware based cache coherency
enforcement uses a priciple called snooping.
Non-Uniform Memory Access (NUMA)
is an architecture where SMP nodes (groups of SMP arranged memory and processors) share
a single memory space. The memory space is, however, distributed/copied across the physical
memory (RAM) of the nodes.
Note that Simultaneous Multi Threading (SMT)
implementations share execution units and bus interface and thus do not
have independent caches.
Hyper-Threading
is Intel's name for SMT.
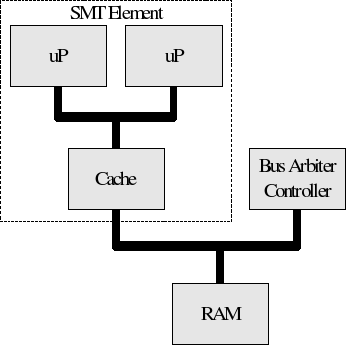
This diagram is slightly misleading in that it implies two complete
processors sharing the same cache. Indeed, this is how such systems logically
appear to software, but in reality the two processor blocks must share execution
units.
A simple SMT system, like the one illustrated here, has no issue
with cache coherency between the two processing elements, since they share
the same cache. However, there is still a desire (not need) for a coherent
bus protocol when the SMT processors must share RAM with a DMA controller
as shown below.
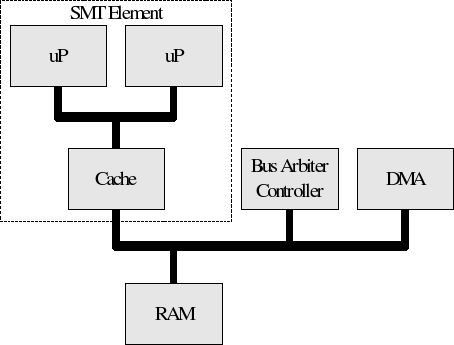
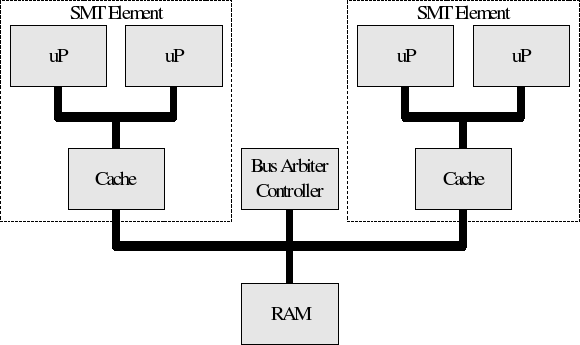
Some systems exhibit attributes of traditional SMP NUMA arrangements, and SMT
as shown below. The Xenon device used in the Xbox 360 has such an architecture
albeit with three SMT elements instead of the two illustrated here.
mike@mnmoran.org