Repository Organization
Introduction
This paper evaluates techniques for organizing files in a reusable
software repository. The ubiquitous hierarchical file system directory
structures are useful for organizing information. Traditionally,
software developers have used directories to organize their
software using containment properties of the file system to keep
together files belonging to a particular software project.
Unfortunately, such an organization, while convenient and familiar, does
not promote software reuse across projects. Treating hierarchical
directory structures as dependency graphs, although a bit
counter-intuitive, allows us to organize source files in a way that
keeps them independent from any particular use, and thus usable in other
project contexts.
Containment
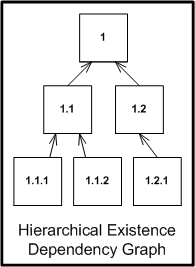
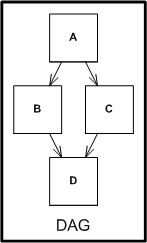
Viewing directory structures as a containment mechanism is a common
practice among software developers. Typically, a root directory
represents the project that often contain the "main" program entry
point. The sub-directories of the project root contain subordinate
files, which contain the subroutines invoked by the main program. This
technique is probably the result of the programmer thinking about file
organization as looking something like the call-graph in a top-down view
of a program.
Unfortunatly, due to the hierarchical nature of the filesystem, such
an organization precludes other projects from using the same files
without first copying the files into the new project. As discussed in my rant on reuse, copying is not reusing, and thus
such an organization is inappropriate within a software reuse context.
Furthermore, a call-graph is a Directed Acyclic Graph (DAG)
structure rather than a simple hierarchical structure since multiple
software modules can reference the same subroutine. This is a common
organizational flaw, and is probably the result of our familiarity with
hierarchical file systems, and our tendency to use that golden hammer as
a solution to all of our organizational problems.
Dependency
If you've read the drivel above, you have probably guessed that I'm
leading up to something. Simply stated, the key to software reuse is
dependency management. To be used in a context other than its original,
a software module must be independent of the original project context.
Reusable software has a dependency graph with a Directed Acyclic Graph
(DAG) structure. That is to say that there are no circular dependencies
in reusable software.
As we discussed above, however, the file systems, where our reusable
source code resides, are hierarchical. Since a DAG is a more generalized
structure, it is not possible to use the hierarchical file system
directly. Rather, it is necessary to find a way to at least prevent the
file organization from creating dependency restrictions. To do this, we
will analyze the dependency properties of hierarchical file systems.
A hierarchical file system is essentially a name space. A file is
identified uniquely by specifying its absolute path name. Relative path
names are a convenience that limit the namespace scope to a particular
sub-tree. Any file or directory contained in another directory is
dependent on the directory that contains it. As evidence, consider what
happens if you attempt to delete the parent directory of a file. Either
a warning is issued, requiring you to delete the contents of the
directory first, or the directory and its contents are deleted. Stated
again, the content of a directory cannot exist without its directory,
and thus the content of the directory is dependent on the directory.
Note that this in contrary to the way that software developers typically
organize their files, where the sub directories of a project contain
files upon which the project depends.
Pathnames in #include Specifications
For various reasons, many C/C++ software organizations refrain from
using directory path specifications in "#include"
statements. Some of the restrictions (e.g. absolute paths) are
reasonable, while others are rooted in history and mythology.
The biggest problem with absolute paths in #include
specifications is that they limit the location and number of private
build trees, and are thus rightly avoided. For examle, if a developer is
to have two views of the same application, with each view having a
different version of the same included file, this would be impossible if
absolute path-names are used. Yes, if you use the Clearcase virtual file
system, this is possible, however, with most other "snapshot" style
repositories, this is a significant problem.
It is, however, quite easy for a build environment to support paths
that are relative to a single variable root. This is easily done using a
common compiler option to specify search paths for include files (e.g.
-I /home/mike/sandbox.)
Another reason that pathnames are avoided in #include
specifications have to do with the character used for directory
seperators. For example, UNIX operating systems use a forward slash '/',
Microsoft operating systems use the backward slash '\', and older Apple
operating systems use a colon ':'.
With the advent of Apple's OSX series of operating system that are UNIX
based, this issue is improving. Even so most compilers for the Apple
Macintosh can handle forward slashes as directory separators in #include
statements. However, if I recall correctly, at least one Macintosh
compiler in the past simply ignored the directory prefix in an #include
specification.
The Microsoft operating systems remain one of the largest impediments
to compatibility. However, most modern compilers (and arguably all significant modern compilers) are
able to work with either forward or backslash separators. The primary
exceptions to this rule being in some compilers that are focused on
small (e.g. 8-bit), or quite specialized processors. However, any
processor supported by the GNU GCC compiler has at least one source of
hope. Thus, while I acknowledge that there still exist circumstances in
which directory separators are still an issue, I will assert that for
common 32-bit processors and even for many 16-bit and 8-bit processors,
directory separators in path-names are no longer an issue.
Lets have a look at the what happens if we do not allow pathnames in #include
specifications. In this case, at least one of two things must be done.
- Copy all header files to a single directory.
- Copy all header files to one of a few directories.
- Add an option to the compiler command for every directory that
has a header file.
First, we could copy all header files to a single location.
- All namespace information must then be encoded into the name of
the header file.
- Historically, we may be limited to 8 character filename sizes.
Approximately (26+10+~10)^8 possible filename combinations, not all of
which are readable/viable/reasonable (imagine all numbered header file
names.) This is a real problem when we consider integration with 3rd
party code whose file names we cannot control. Not everyone is as namespace conscious as
we are.
Posix/UNIX interfaces and the Linux kernel are two major places where
pathnames are used in the source code. For example, #include
<sys/types.h> is required for the open system
call.
As discussed above, the hierarchical file system is a name-space, which
can be useful in maintaining a repository for software reuse.
Organizational Examples
The sections that follow present common useful organizational patterns.
Alternative Interface Implementation
This example of file organization arises from a particular type of
abstraction involving simple compile-time binding. It is common, for the
purpose of module portability across platforms, for an interface to be
defined (e.g. a set of functions and types) and placed in a header file.
The interface is then implemented for various other platforms in one or
more source (e.g. .c) files.
It is a common practice and mistake to place all of the files for a
module in a single directory. However, such an organization leads to an
undesirable dependency created by the files being located in the same
directory.
There are issues with compiling implementation (.c) files in the same
directory with the header file describing the interface. Assume that
there is a build file for each directory listing the files to be
compiled that is shared by all project clients, for example a makefile
in the directory with the sources. If more than one implementation of
the interface is located in the directory, how will the build system
choose which variant to build and link with the application. Although
it may be possible to perform magic in the build environment, such
solutions become quickly untenable and will need some amount of
customization for each instance.
A better solution is to have the interface header located in one
directory, and each alternate implementation located in its own
directory. The implementation directories may be located in a sub
directory of the interface header file, or in any other directory not
in the dependency path of the interface header file (i.e. a parent
directory of the interface header file.)
[FIXME: finish this thread]
[mention the notion of "module" with respect to a single directory and
reuse]
Creational Interface Segregation
[Make this a separate paper]
This is a rant about the importance of separating the creational
interfaces of a module from its operational interfaces.
Forward declared types in the operational interface, actual/concrete
types known by the creational interface.
mike@mnmoran.org